MGnify Proteins Resource
MGnify Proteins Resource
Introduction
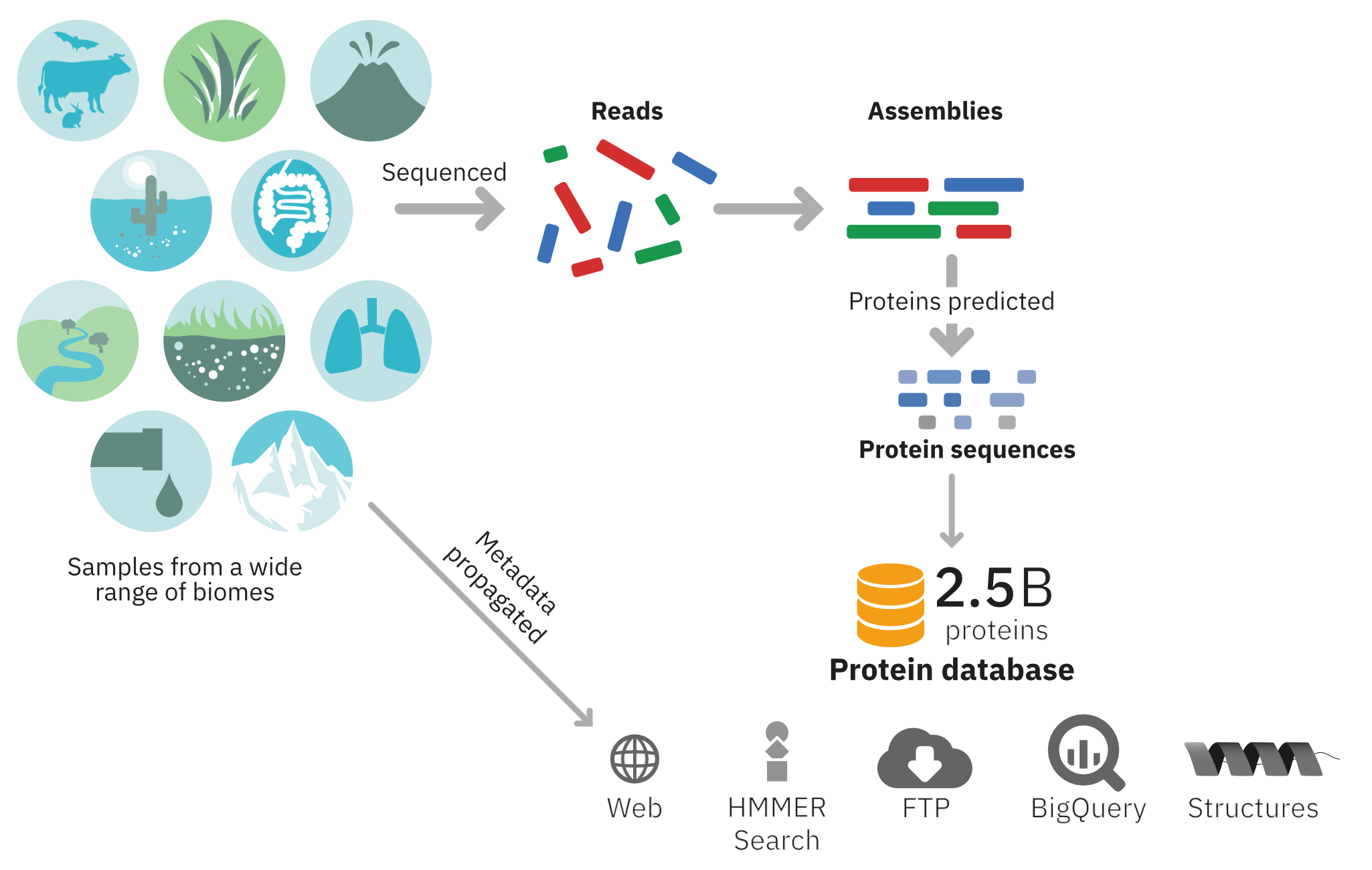
The MGnify Protein Database comprises sequences predicted from assemblies generated from publicly available metagenomic datasets. Since its initial release in August 2017, which comprised just under 50 million sequences, it has grown to over 5.7 billion sequences. All sequences have stable accessions, prefixed with MGYP, such as MGYP000261684433. Due to the dataset’s size, sequences are clustered at 90% and 30% identity using DIAMOND/Linclust. Despite clustering, the sequences still capture the biological complexity inherent in metagenomic data.
The dataset is accessible via several platforms:
- FTP Server: Available for download from our FTP server.
- HMMER Sequence Search Webservice: Accessible through our Sequence Search service.
- MGnify Proteins Portal: Explore the data on the MGnify Proteins web portal.
- Google Cloud Public Dataset: Available as a Big Query public dataset on Google Cloud.
The latest release (2026_07) is available on the FTP, and is used in the HMMER Sequence Search, MGnify Proteins Portal. The Google Cloud Public (GCP) dataset is still on the 2024-04 release. We are working hard to update the GCP dataset to the newest release as soon as possible.
License
The data is available for both academic and commercial use under a CC0 1.0 Universal License.
If you make use of the MGnify Protein Database, please cite the following paper:
- Richardson, L., Allen, B., Baldi, G., Beracochea, M., Bileschi, M. L., Burdett, T., Burgin, J., Caballero-Pérez, J., Cochrane, G., Colwell, L. J., Curtis, T., Escobar-Zepeda, A., Gurbich, T. A., Kale, V., Korobeynikov, A., Raj, S., Rogers, A. B., Sakharova, E., Sanchez, S., Wilkinson, D. J., Finn, R. D. MGnify: the microbiome sequence data analysis resource in 2023. Nucleic Acids Research (2023). https://doi.org/10.1093/nar/gkac1080
Citation
@online{2026,
author = {, MGnify},
title = {MGnify {Proteins} {Resource}},
date = {2026-07-13},
url = {https://docs.mgnify.org/src/docs/mgnify-proteins.html},
langid = {en}
}